import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
heart = pd.read_csv('heart.csv')사용할 라이브러리들을 import하고 heart에 파일을 읽는다.
list(heart.columns)열 이름들을 확인한다.

heart.head(3)데이터 분석을 하기 전에 데이터셋의 앞 부분이나 뒷 부분을 확인하는 것은 중요하다.

심부전 데이터셋의 목적은 심장병의 유무를 예측하거나 관련된 패턴을 분석하는 것
가장 중요한 변수는 심장병 여부를 나타내는 HeartDisease 변수이다. 결측값들도 잘 확인한다.
heart.info()열 요약 정보를 확인한다.
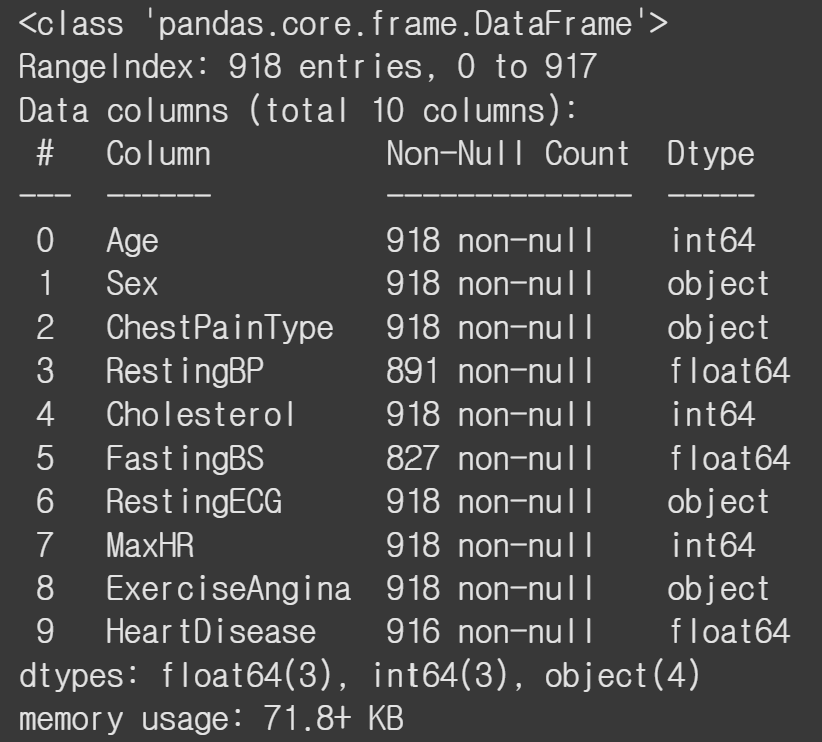
918개의 행과 10개의 열이 있고, RestingBP, FastingBS, HeartDisease 열에 결측값들이 있는 것을 알 수 있다.
for i in heart.columns:
missingValueRate = heart[i].isna().sum() / len(heart) * 100
if missingValueRate > 0:
print("{0} null rate: {1}%".format(i, round(missingValueRate, 2)))for문을 사용하여 열 별로 결측값들의 비율을 계산한다.

총 918개의 행이므로 데이터가 적어 HeartDisease 열만 결측값들을 삭제하고 나머지 두 열은 결측값들을 대체한다.
heart['FastingBS'] = heart['FastingBS'].fillna(0)
heart['RestingBP'] = heart['RestingBP'].replace(np.nan, heart['RestingBP'].median())
heart.dropna(axis = 0, inplace=True)FastingBS 열을 결측값들을 0으로 대체하고, RestingBP 열은 중앙값으로 대체한다.
HeartDisease는 dropna를 통해 삭제하고 원본 데이터프레임을 수정한다.
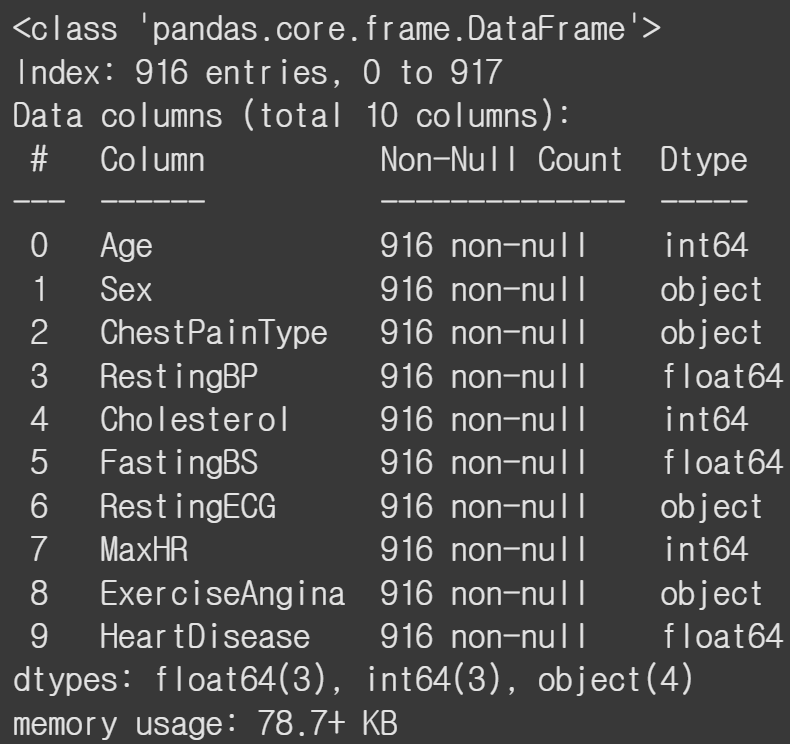
결측치들을 처리한 후에는 잘 처리되었는지 확인하는 것이 중요하다. 총 916개의 행으로 다 잘 처리된 것을 알 수 있다.
print(heart['MaxHR'].mean())
print(heart['MaxHR'].median())MaxHR열의 평균과 중앙값을 확인한다.
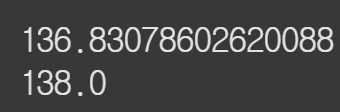
큰 차이가 없다. 분포가 대체로 균형 잡혀 있음을 알 수 있다. 평균과 중앙값이 비슷하면 데이터에 극단적인 이상치가 많지 않다는 것을 의미하고, 큰 왜곡 없이 고르게 있다는 것을 나타낸다.
heart['ChestPainType'].value_counts()열의 빈도수를 확인한다.

가장 많이 나온 결과는 ASY(무증상)인 것을 알 수 있다.
heart[['Age', 'MaxHR', 'Cholesterol']].describe()describe()를 통해 Age, MaxHR, Cholesterol 열의 통계 요약을 본다.
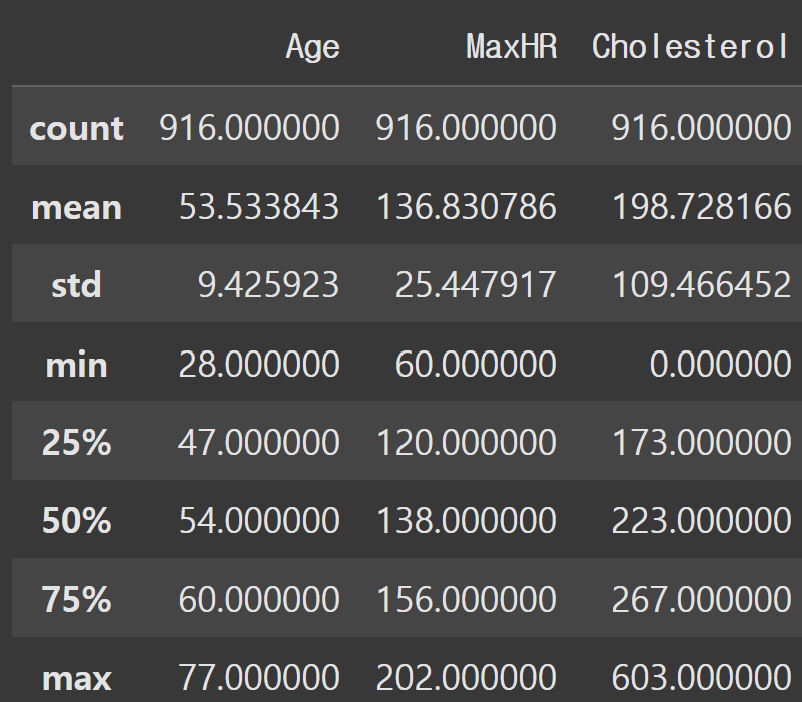
Age의 평균값이 53.53으로 대부분 50대 초반인 것을 알 수 있다.
Cholesterol의 표준편차는 평균과 비교했을 때 비교적 큰데, 이것을 통해 평균 주변에 데이터가 넓게 분포되어 있다는 것을 알 수 있다.
heart.groupby(['HeartDisease', 'ChestPainType'])[['Age', 'MaxHR', 'Cholesterol']].mean()그룹별 집계를 통해 특정 기준에 따른 평균값, 합계, 개수 등을 계산하거나 그룹별 데이터의 분포를 분석할 수 있다.
심장병 유무와 흉통 유무에 따른 나이, 최대 심박수, 콜레스테롤 수치를 본다.

heart.groupby('Sex')['RestingBP'].mean()성별에 따른 RestingBP의 평균값을 확인한다.

거의 비슷한 것을 알 수 있다. 이 데이터를 통해서는 성별에 따른 것보다는 개인에 따른 상태가 더 중요하다고 볼 수 있다.
ratio = heart['ChestPainType'].value_counts()
plt.pie(x=ratio, labels = ratio.index, autopct='%0.f%%', startangle=100, explode=[0.05, 0.05, 0.05, 0.05], shadow=True, colors=['#003399', '#0099FF', '#00FFFF', '#CCFFFF'])
plt.suptitle('Chest Pain Type distribution', fontfamily='serif', fontsize=15, fontweight='bold')
plt.title('We see that the ratio is occupied in the following order: ASY, NAP, ATA, TA.', fontfamily='serif', fontsize=12)
plt.show()흉통 유형을 카테고리화하고 파이차트로 표현한다.
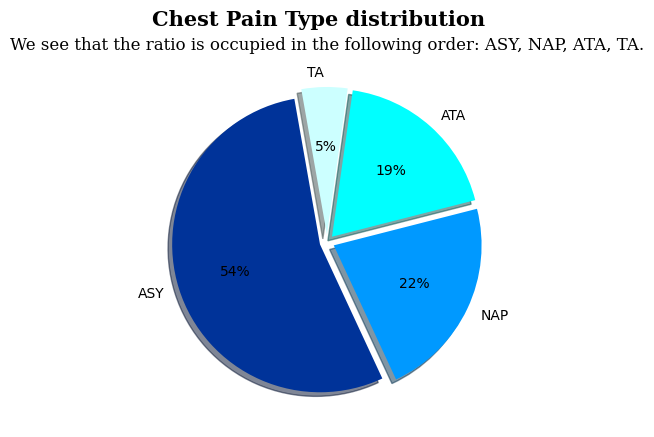
ASY가 비율이 제일 높은 것을 알 수 있다. 심장병 진단 시 무증상 흉통을 고려해야 할 필요성이 크다는 것을 알 수 있다.
NAP와 ATA의 비율도 적지 않은데, 이를 통해 심장병 진단 시 흉통 유형을 분석하는 것이 중요하다고 할 수 있다.
TA는 비율이 가장 적으므로 심장병 환자들 사이에서 TA가 아닌 다른 형태의 흉통이 더 흔할 수 있다는 것을 시사한다.
plt.figure(figsize=(12, 5))
sns.countplot(data=heart, x='HeartDisease', hue='ChestPainType', hue_order=['ASY', 'NAP', 'ATA', 'TA'], palette=['#003399', '#0099FF', '#00FFFF', '#CCFFFF'])
plt.suptitle('Chest Pain Types Based on Presence of Heart Disease', fontfamily='serif', fontsize=15, fontweight='bold')
plt.title('The chest pain types vary depending on the presence of heart disease. \nFor individuals with heart disease, the types are ASY, NAP, ATA, and TA in that order. \nFor individuals without heart disease, the types are ATA, NAP, ASY, and TA in that order.',
fontfamily='serif', fontsize=12, pad = 15)
plt.xticks([0, 1], ['For individuals without heart disease', 'For individuals with heart disease'])
plt.tight_layout()
plt.show()심장병 여부에 따른 흉통 유형을 빈도 그래프를 통해 시각화한다.

심장병 유무에 따른 흉통 유형의 분포가 다름을 알 수 있다.
심장병 환자의 경우, ASY, NAP, ATA, TA 순으로 나타나고, 비환자의 경우에는 ATA, NAP, ASY, TA 순으로 나타난다.
심장병 환자의 경우 ASY의 비율이 매우 높게 나타나는데, 이를 통해 무증상 환자에 대한 모니터링을 강화하고, 조기 검진을 통해 심장병을 조기 발견하는 것이 중요하다는 것을 알 수 있다.
Heart_Age = heart.groupby('Age')['HeartDisease'].value_counts().unstack(level='HeartDisease')연령대에 따른 심장병 유무의 빈도수를 집계하고 다시 그룹화를 풀어 Age를 인덱스로, HeartDisease를 열로 가지는 데이터프레임을 Heart_Age 변수에 저장한다.

plt.figure(figsize=(15, 5))
plt.fill_between(x=Heart_Age[0].index, y1=0, y2=Heart_Age[0], color='#003399', alpha=1, label='Normal')
plt.fill_between(x=Heart_Age[1].index, y1=0, y2=Heart_Age[1], color='#0099FF', alpha=0.8, label = 'heart disease')
plt.legend()
plt.xlabel('Age')
plt.ylabel('Count')
plt.suptitle('Age Based on Presence of Heart Disease', fontfamily='serif', fontsize=15, fontweight='bold')
plt.title('As age increases, the presence of heart disease becomes more prevalent.', fontfamily='serif', fontsize=12)
plt.show()영역 채우기 그래프를 통해 연령대에 따른 심장병의 유무와 분포의 변화를 살펴본다.
Heart_Age[0]은 심장병이 없는 환자의 연령 데이터, Heart_Age[1]은 심장병이 있는 환자의 연령 데이터이다.
y1=0은 아래쪽 채우기 영역의 범위를 지정하고, y2는 위쪽 채우기 영역의 범위를 지정한다.
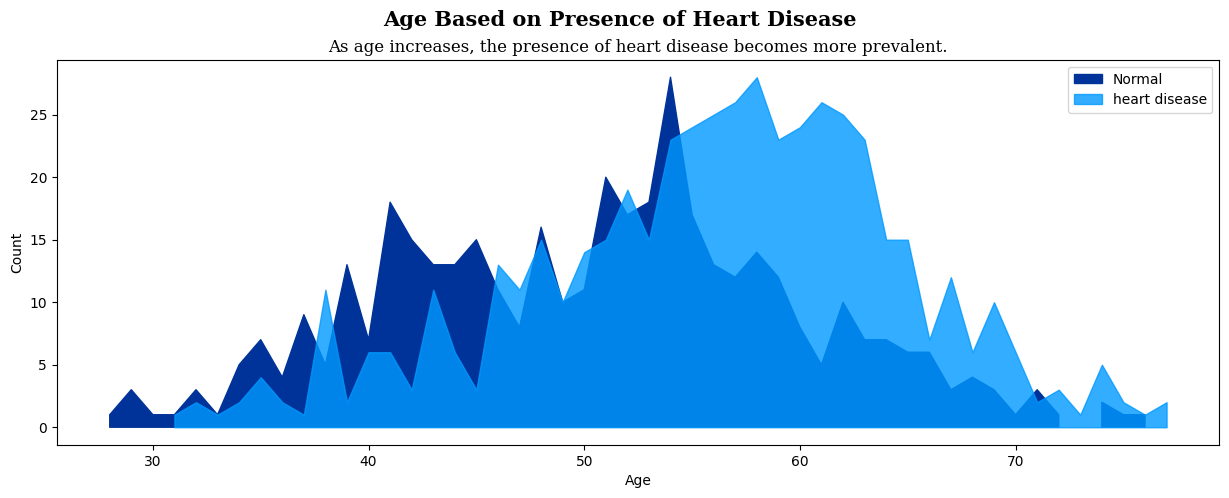
그래프를 통해 50대에서 70대 사이에 빈도가 높은 것을 알 수 있다. 보통 50대 이후로 많이 발생하는 경향을 파악할 수 있는데, 단순히 빈도가 높다는 이유로 심장병 발생률이나 위험 수준이 높다고 할 수는 없다. 해당 연령대에 속한 환자 수가 많으면 빈도수가 높아지기 때문이다. 빈도와 발생률을 혼동하지 않도록 주의해야 한다. 발생률이나 위험도를 보려면 전체 인구 대비 심장병 환자의 비율을 확인해야 한다.
H_0 = heart[heart['HeartDisease'] == 0]
H_1 = heart[heart['HeartDisease'] == 1]심장병이 있는 환자와 없는 환자 데이터를 각각 H_1, H_0에 저장한다.
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
sns.swarmplot(x='RestingECG', y='Age', data=H_0, ax=ax1, hue='ExerciseAngina', palette=['#003399', '#0099FF'], hue_order=['Y', 'N'])
sns.swarmplot(x='RestingECG', y='Age', data=H_1, ax=ax2, hue='ExerciseAngina', palette=['#003399', '#0099FF'], hue_order=['Y', 'N'])
plt.suptitle('Resting electrocardiogram Based on Presence of Heart Disease', fontfamily='serif', fontsize=15, fontweight='bold')
ax1.set_title('Without heart disease')
ax2.set_title('With heart disease')
plt.show()심장병 발병 여부에 따른 환자군을 swarmplot을 통해 범주형 산점도 그래프로 시각화한다.
x축에는 RestingECG, y축에는 연령을 사용한다.
hue= 'ExerciseAngina'를 통해 운동 시 협심증 여부에 따라 데이터를 구분한다.

위 그래프를 통해 심장병 존재 여부에 따라 RestingECG와 Age의 관계를 시각적으로 비교할 수 있다.
50~60대의 H_0의 경우, RestingECG가 Normal, LVH, ST순서로 분포되어 있다.
H_1의 경우에는 Normal, ST, LVH 순으로 분포되어 있다. 이를 통해 심장병이 있는 경우에는 ST의 경우가 더 많음을 알 수 있다. 이러한 분석을 통해 연령과 심전도 패턴을 통해 심장병의 발생 가능성을 조기에 발견할 수 있다.
pubmed_title = pd.read_csv('pubmed_title.csv')
from wordcloud import WordCloud
from PIL import Image
plt.figure(figsize=(10, 5))
text = str(list(pubmed_title['Title']))
mask = np.array(Image.open('image.jpg'))
cmap = plt.matplotlib.colors.LinearSegmentedColormap.from_list("", ['#000066','#003399', '#00FFFF'])
wordcloud = WordCloud(background_color='white', width=2500, height=1400, max_words=170, mask=mask, colormap=cmap).generate(text)
plt.imshow(wordcloud)
plt.axis('off')
plt.suptitle('Heart Disease Wordcloud', fontweight='bold', fontfamily='serif', fontsize=15)
plt.title('Title of abstract in Pubmed site: Heart Failure', fontfamily='serif', fontsize=12)
plt.show()넷플릭스 데이터 분석에서와 동일한 방식으로 워드 클라우드를 구현한다.

heart failure, patient, ejection fraction, ventricular와 같은 단어들을 확인할 수 있다.
'데이터 분석 > 파이썬 데이터 분석가 되기+챗GPT' 카테고리의 다른 글
| 06장 넷플릭스 데이터 분석 프로젝트 (0) | 2025.02.23 |
|---|---|
| 5장 연습문제 (0) | 2025.02.16 |
| 05장 웹 데이터 수집 라이브러리, 뷰티풀수프 (0) | 2025.02.16 |
| 4장 연습문제 (0) | 2025.02.08 |
| 04장 데이터 시각화 라이브러리, 시본 (0) | 2025.02.08 |



