import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns사용할 라이브러리들을 불러와서 별칭으로 지정한다.
netflix = pd.read_csv('netflix_titles.csv')
netflix.head()
list(netflix.columns) #열 이름 확인
netflix.head(3)
netflix.info() #요약 정보 확인데이터셋을 불러와서 간단하게 확인한다.
for i in netflix.columns:
missingValueRate = netflix[i].isna().sum() / len(netflix) * 100
if missingValueRate > 0:
print("{} null rate: {}%".format(i, round(missingValueRate, 2)))결측치 비율을 확인한다.
netflix['country'] = netflix['country'].fillna('No Data')
netflix['director'] = netflix['director'].replace(np.nan, 'No Data')
netflix['cast'] = netflix['cast'].replace(np.nan, 'No Data')
netflix.dropna(axis = 0, inplace=True)결측치 값을 대체하거나 아예 삭제한다. 원본 데이터에 직접 수정하여 일관성을 유지하고 혼란을 줄인다.
netflix.info()
netflix.isna().sum()위와 같이 결측치가 잘 처리 되었는지 확인한다.
피처 엔지니어링: 데이터프레임의 기존 변수를 조합하거나 변형하여 새로운 변수를 만드는 것
매우 중요한 단계, 예측 모델이 데이터의 패턴을 잘 이해하고 학습할 수 있도록 돕는다.
의미 있는 피처를 만들면 모델의 결과를 쉽게 해석할 수 있다.
데이터의 다양한 측면을 고려하여 더 정확한 분석을 할 수 있다.
netflix['age_group'] = netflix['rating']
age_group_dic = {
'G': 'All',
'TV-G': 'All',
'TV-Y': 'All',
'PG': 'Older Kids',
'TV-Y7': 'Older Kids',
'TV-Y7-FV': 'Older Kids',
'TV-PG': 'Older Kids',
'PG-13': 'Teens',
'TV-14': 'Young Adults',
'NC-17': 'Adults',
'NR': 'Adults',
'UR': 'Adults',
'R': 'Adults',
'TV-MA': 'Adults'
}
netflix['age_group'] = netflix['age_group'].map(age_group_dic)rating 열의 내용을 직관적으로 이해하기 어려우므로 딕셔너리 형태를 사용하여 위와 같이 대체한다.
map() 함수를 사용하여 rating 컬럼의 각 값을 딕셔너리에 정의된 값으로 변환한다.
map() 함수는 딕셔너리의 키를 기준으로 원래 값을 변환한다.
type_counts = netflix['type'].value_counts()
print(type_counts)
plt.figure(figsize=(5, 5))
plt.pie(type_counts, labels=type_counts.index, autopct='%0.f%%', startangle=100, explode=[0.05, 0.05], shadow=True, colors=['#b20710', '#221f1f'])
plt.suptitle('Movie & TV Show distribution', fontfamily='serif', fontsize=15, fontweight='bold')
plt.title('We see more movies than TV shows on Netflix.', fontfamily='serif', fontsize=12)
plt.show()type열에 해당하는 데이터로 파이 차트를 만든다.

넷플릭스 사용자는 영화 카테고리에 대한 관심이나 소비가 더 크다는 것을 알 수 있다.
영화 관련 콘텐츠나 제품에 대한 마케팅 전략을 더 신중하게 수립해야 한다.
genres = netflix['listed_in'].str.split(', ', expand=True).stack().value_counts()listed_in 열에 있는 내용을 문자열로 변환하고 split()을 통해 ,로 구분한다.
expand=True는 분할된 결과를 확장하여 여러 열로 변환한다.
stack()을 사용하면 여러 열로 구성한 데이터프레임을 1개의 열로 만들어 쌓는다.
value_counts()로 횟수를 센다.
plt.figure(figsize=(12, 6))
sns.barplot(x=genres.values, y=genres.index, hue=genres.index, palette='RdGy')
plt.title('Distribution of Genres for Movies and TV Shows on Netflix', fontsize=16)
plt.xlabel('Count', fontsize=14)
plt.ylabel('Genre', fontsize=14)
plt.grid(axis='x')
plt.show()x에 장르의 등장 횟수, y에 장르의 이름을 지정하고, hue로 장르를 분류한다.
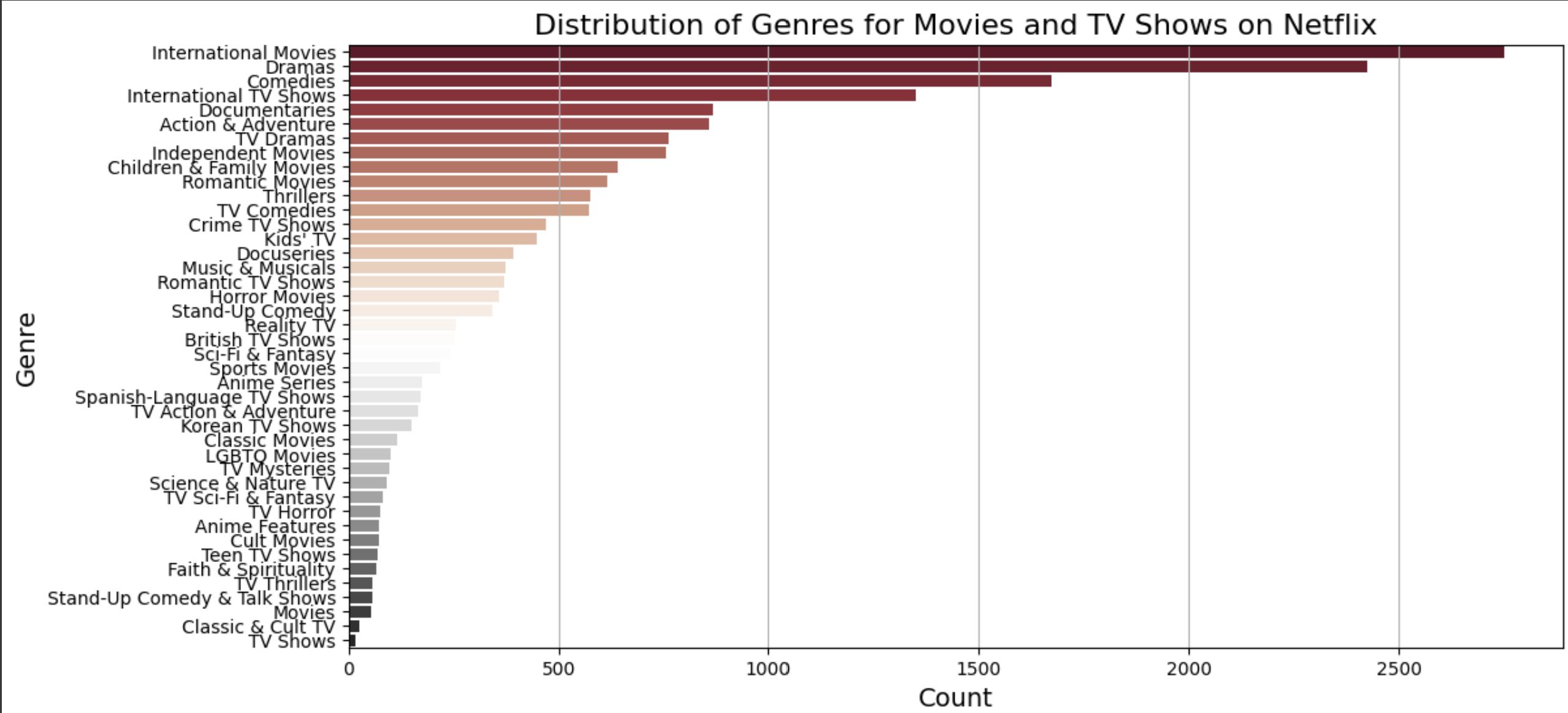
가장 큰 비중을 차지하는 장르를 알 수 있다. 드라마와 국제 영화에 집중되어 있다.
pd.set_option('display.max_rows', None)
netflix['country'] = netflix['country'].str.split(', ')
netflix_age_country = netflix.explode('country')pd.set_option() 함수는 판다스 라이브러리의 출력 옵션을 설정한다.
display.max_rows를 None으로 설정하면 출력할 때 모든 행을 출력한다.
country열을 문자열로 변화해서 ,로 구분한다.
explode() 함수를 적용하여 개별 행으로 분리한다.
netflix_age_country_unstack = netflix_age_country.groupby('age_group')['country'].value_counts().unstack()각 나이 그룹에 따른 국가별 넷플릭스 콘텐츠 수를 구한다.
unstack()을 통해 그룹화된 데이터를 풀어서 다시 데이터프레임 형태로 만든다.
age_group열은 인덱스, country열을 열로 만든 데이터프레임을 만든다.
age_order = ['All', 'Older Kids', 'Teens', 'Adults']
country_order = ['United States', 'India', 'United Kingdom', 'Canada', 'Japan',
'France', 'South Korea', 'Spain', 'Mexico', 'Turkey']
netflix_age_country_unstack = netflix_age_country_unstack.loc[age_order, country_order]
netflix_age_country_unstack = netflix_age_country_unstack.fillna(0)age_order와 country_order에 있는 값들로만 데이터를 필터링하고 결측치를 처리한다.
netflix_age_country_unstack = netflix_age_country_unstack.div(netflix_age_country_unstack.sum(axis=0), axis=1)sum(axis=0)으로 열 방향으로 합을 구하고 div()의 axis 매개변수에 1을 전달해 각 열의 값을 열의 합으로 나눠 비율을 구한다.
cmap = plt.matplotlib.colors.LinearSegmentedColormap.from_list('', ['#221f1f','#b20710','#f5f5f1'])
sns.heatmap(netflix_age_country_unstack, cmap = cmap, linewidth=2.5, annot=True, fmt='.0%')LinearSegmentedColormap.from_list()함수를 통해 사용자 정의 컬러맵을 만들고 히트맵을 만든다.
annot은 각 셀에 숫자를 표시한다. fmt는 숫자를 표시할 때 백분율 형식으로 표시하도록 지정한다.
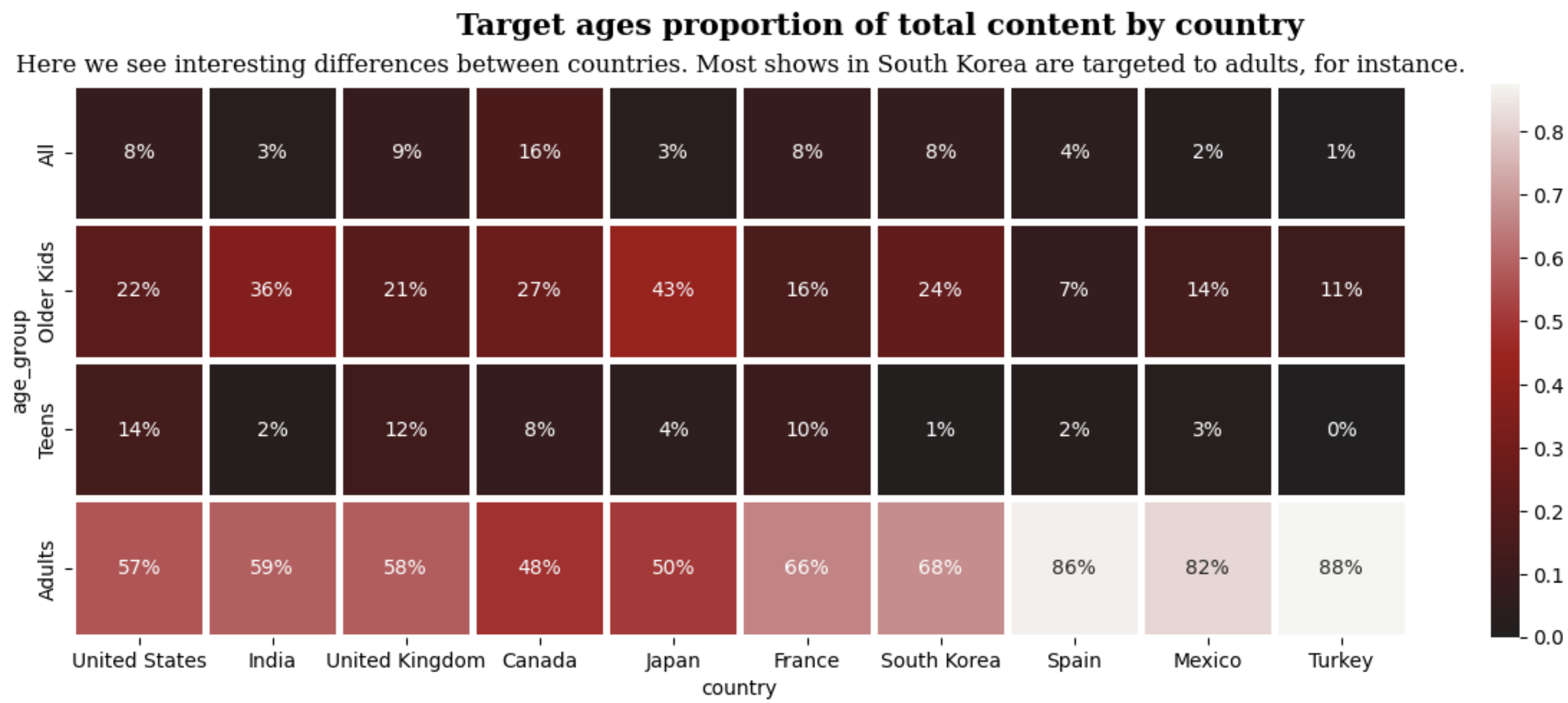
모든 국가에서 성인 이용자가 가장 많은 걸 알 수 있다.
United States와 Canada는 모든 나이 그룹이 고르게 있다. India나 Japan은 Older Kids의 비율이 높다.
from wordcloud import WordCloud
from PIL import Image워드 클라우드: 텍스트 데이터의 빈도나 중요도를 이용하여 데이터를 시각화하는 방법
워드 클라우드를 사용하기 위한 라이브러리들을 가져온다.
text = str(list(netflix['description']))
mask = np.array(Image.open('netflix_logo.jpg'))
wordcloud = WordCloud(background_color= 'white', width = 1400, height = 1400, max_words= 170, mask = mask, colormap=cmap).generate(text)
plt.imshow(wordcloud)
plt.axis('off')description열을 리스트로 변환 후 문자열로 변환한다.
로고 이미지를 열고 넘파이 배열로 변환한다.
WordCloud() 함수를 사용하여 워드 클라우드를 생성한다. mask는 워드 클라우드의 모양을 지정하는 마스크 이미지이다.
generate(text)를 통해 text에 담긴 문자열로 워드 클라우드를 생성한다.
imshow()로 이미지로 표시한다. axis('off')로 축을 표시하지 않는다.

자주 사용하는 단어가 크게 보이는데, life, find, love, world와 같은 단어들이 가장 많이 나온다는 것을 알 수 있다.
'데이터 분석 > 파이썬 데이터 분석가 되기+챗GPT' 카테고리의 다른 글
| 07장 의료 데이터 분석 프로젝트 (1) | 2025.03.01 |
|---|---|
| 5장 연습문제 (0) | 2025.02.16 |
| 05장 웹 데이터 수집 라이브러리, 뷰티풀수프 (0) | 2025.02.16 |
| 4장 연습문제 (0) | 2025.02.08 |
| 04장 데이터 시각화 라이브러리, 시본 (0) | 2025.02.08 |



