1번


2번


kind='scatter'이 기본형이라 적지 않았는데 기본이어도 따로 적어두는게 더 직관적이라서 적어야겠다.
title을 써서 y값을 직접 실행해가며 맞춰봤는데 suptitle도 사용할 수 있다는 걸 알아두자.
3번


suptitle하고도 y값을 따로 정해줘야 제목이 보기 편하게 조정되는 것 같다.
diag_kind를 kde로 따로 지정해줬는데 안 했는데도 자동으로 kde가 나오는 이유를 챗gpt에게 물어봤다.
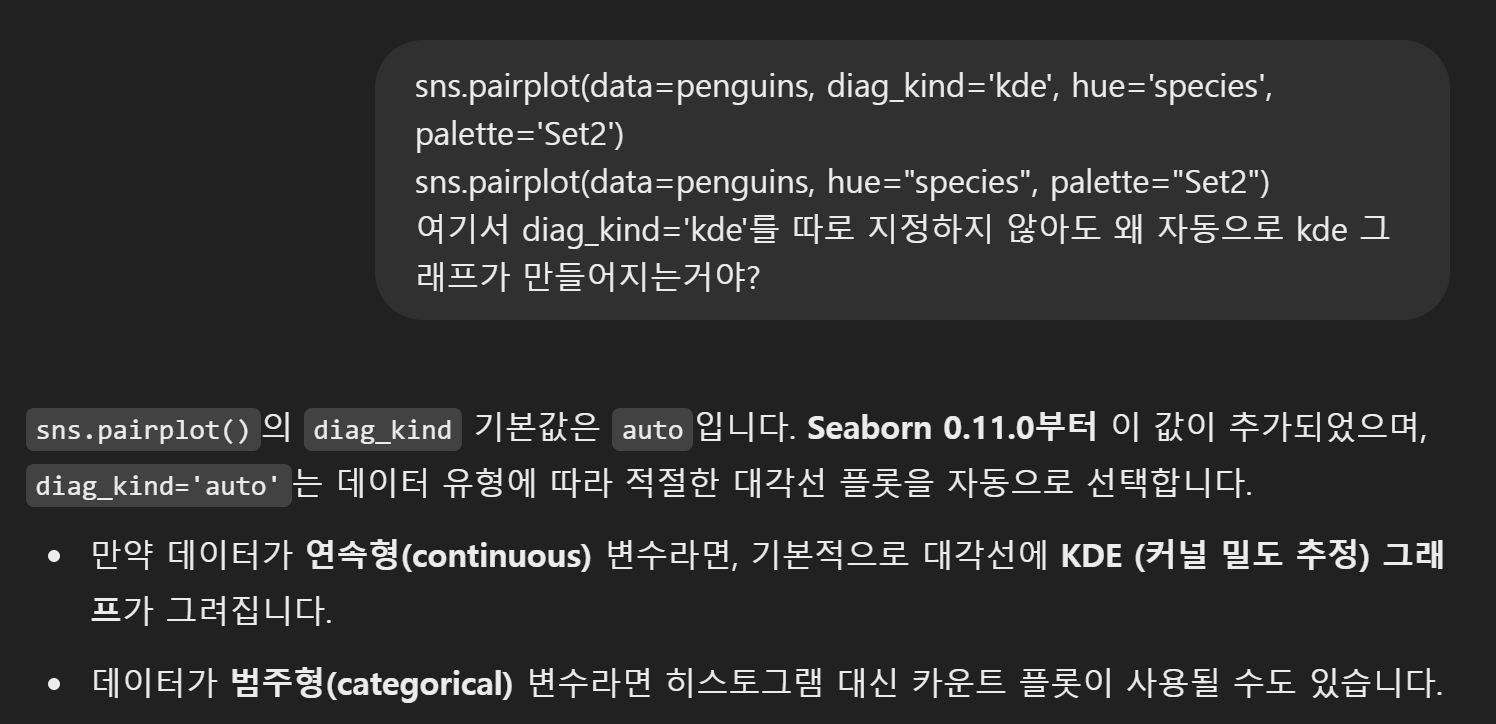

penguins 데이터셋의 변수들이 연속형이기 때문에 자동값이 kde로 설정되어 따로 지정하지 않아도 되는 것을 알게 되었다.
'데이터 분석 > 파이썬 데이터 분석가 되기+챗GPT' 카테고리의 다른 글
| 5장 연습문제 (0) | 2025.02.16 |
|---|---|
| 05장 웹 데이터 수집 라이브러리, 뷰티풀수프 (0) | 2025.02.16 |
| 04장 데이터 시각화 라이브러리, 시본 (0) | 2025.02.08 |
| 3장 연습문제 (0) | 2025.01.25 |
| 03장 데이터 시각화 라이브러리, 맷플롯립 (0) | 2025.01.25 |



